Internet, vaste réseau mondial qui connecte des milliards d'appareils, repose sur des systèmes complexes pour fonctionner. Comprendre sa structure fait appel à divers éléments interconnectés qui travaillent ensemble pour faciliter la navigation, les recherches et le transfert de données que nous utilisons quotidiennement. Parmi ces éléments, les bases de données constituent un pilier majeur du web moderne, stockant l'immense quantité d'informations que nous consultons à chaque instant.
L'infrastructure fondamentale d'Internet
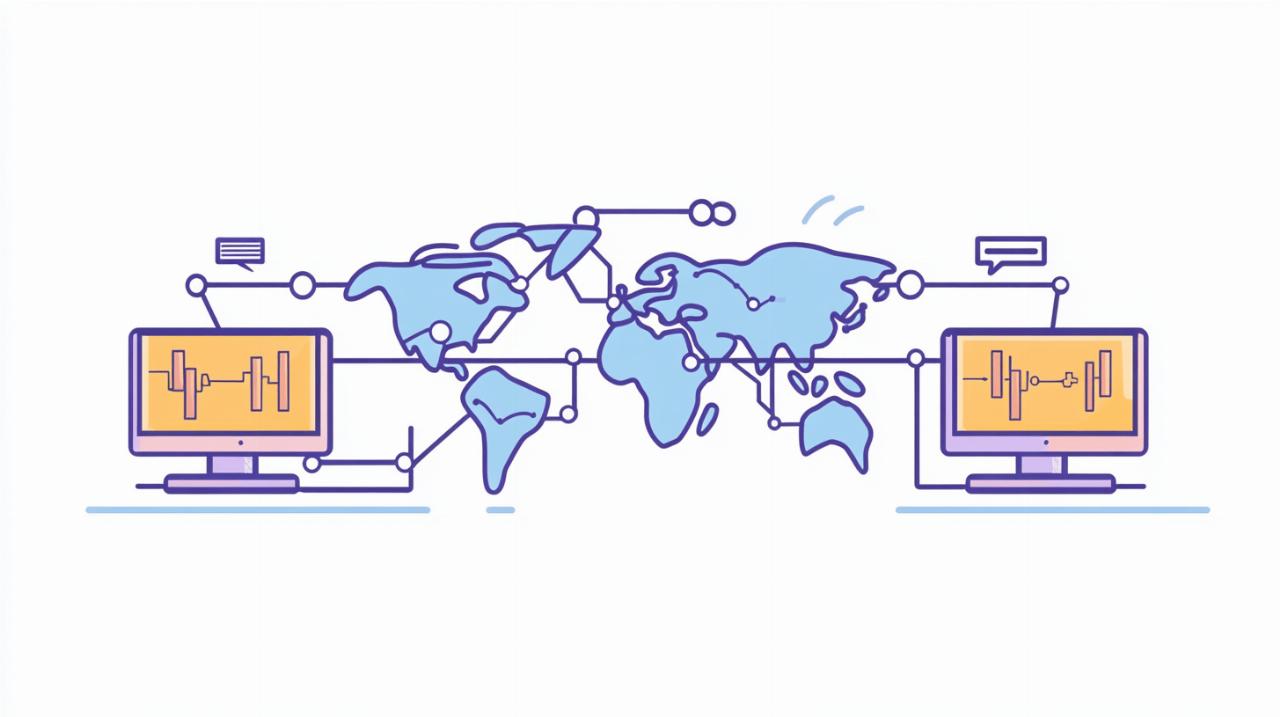
Internet représente un immense réseau d'ordinateurs qui communiquent via des protocoles standardisés. Cette architecture s'appuie sur différentes technologies qui transportent les données d'un point à un autre. À la différence du Web qui constitue un réseau d'informations basé sur l'hypertexte, Internet forme l'infrastructure physique qui rend possible ces échanges numériques.
Les serveurs et leur fonction dans le réseau mondial
Les serveurs jouent un rôle central dans l'architecture d'Internet. Ces machines puissantes stockent les informations et les rendent accessibles aux utilisateurs. Parmi ces informations, on trouve les bases de données qui organisent les données selon différents modèles (SQL, NoSQL). Les serveurs hébergent aussi les sites web, applications et services que nous utilisons. Regroupés dans des centres de données ou Data Centers, ils fonctionnent en continu pour répondre aux requêtes des utilisateurs. Un serveur peut gérer plusieurs types de données : structurées comme dans les bases de données relationnelles, ou non structurées comme dans les systèmes NoSQL adaptés au Big Data.
Le rôle des routeurs dans la transmission des données
Les routeurs agissent comme des aiguilleurs dans le réseau Internet. Leur fonction principale consiste à diriger les paquets de données vers leur destination finale en utilisant le chemin le plus approprié. Quand un utilisateur demande une information stockée dans une base de données, cette requête voyage à travers de multiples routeurs avant d'atteindre le serveur qui l'héberge. Une fois que le serveur a traité la demande, la réponse suit un parcours similaire pour revenir vers l'utilisateur. Les routeurs communiquent entre eux pour déterminer les itinéraires optimaux, créant ainsi un réseau maillé qui assure la fiabilité d'Internet même si certaines connexions tombent en panne.
Les protocoles de communication sur Internet
Internet fonctionne grâce à un ensemble de règles et conventions qui permettent aux ordinateurs de communiquer entre eux. Ces règles, appelées protocoles, constituent le fondement de l'échange d'informations sur le réseau mondial. Les protocoles définissent comment les données sont formatées, transmises, reçues et interprétées par les différents appareils connectés. Sans ces protocoles standardisés, Internet tel que nous le connaissons ne pourrait pas fonctionner. Les bases de données, qui stockent et organisent l'information, s'appuient sur ces protocoles pour échanger des données à travers le réseau.
Le TCP/IP, langage universel du web
Le TCP/IP (Transmission Control Protocol/Internet Protocol) représente le socle fondamental des communications sur Internet. Ce duo de protocoles fonctionne comme un système postal numérique. L'IP attribue une adresse unique à chaque appareil connecté au réseau, semblable à l'adresse d'un domicile. Le TCP, quant à lui, s'assure que les données envoyées arrivent intactes à destination, en divisant l'information en petits paquets numérotés puis en les réassemblant dans le bon ordre.
Ce protocole a été développé dans les années 1970 et adopté par ARPANET (l'ancêtre d'Internet) en 1983. Sa robustesse vient de sa capacité à trouver automatiquement des chemins alternatifs lorsqu'une partie du réseau tombe en panne. Les administrateurs de bases de données SQL et NoSQL utilisent quotidiennement cette technologie pour garantir que les requêtes et les résultats voyagent correctement entre les serveurs et les clients. Un Data Engineer configurant un système ETL pour transférer des données vers un entrepôt de données s'appuie sur la fiabilité du TCP/IP pour assurer l'intégrité des informations transmises.
Le HTTP et HTTPS pour la navigation sécurisée
Le HTTP (HyperText Transfer Protocol) est le protocole qui régit les échanges entre les navigateurs web et les serveurs. Né au début des années 1990 avec Tim Berners-Lee, ce protocole a révolutionné Internet en rendant possible le Web basé sur l'hypertexte. Lorsque vous saisissez une URL dans votre navigateur, le HTTP envoie une requête au serveur approprié qui répond en transmettant la page web demandée.
Face aux problèmes de sécurité du HTTP, le HTTPS (HTTP Secure) a été développé. Il ajoute une couche de chiffrement SSL/TLS qui protège les données échangées entre l'utilisateur et le site web. Cette protection est particulièrement importante pour les applications qui manipulent des données sensibles stockées dans des bases de données, comme les informations bancaires ou personnelles.
Les systèmes de gestion de bases de données (SGBD) modernes intègrent des mesures de sécurité compatibles avec HTTPS. Par exemple, un Data Analyst utilisant Power BI pour visualiser des données issues d'une base SQL accède à ces informations via une connexion HTTPS sécurisée. De même, les applications cloud qui stockent des données structurées et non structurées s'appuient sur ces protocoles pour garantir la confidentialité des échanges. Cette sécurisation est d'autant plus nécessaire à l'ère du Big Data, où d'énormes volumes d'informations transitent constamment sur les réseaux.
Le stockage et la gestion des données en ligne
 Internet repose sur un vaste système de stockage et d'organisation des informations. Les bases de données constituent le socle invisible mais fondamental de notre expérience en ligne. Elles permettent aux sites web et applications de stocker, organiser et récupérer rapidement les informations que nous consultons chaque jour. Sans ces structures organisées, il serait impossible de naviguer sur des sites de commerce, d'utiliser les réseaux sociaux ou même de consulter ses emails.
Internet repose sur un vaste système de stockage et d'organisation des informations. Les bases de données constituent le socle invisible mais fondamental de notre expérience en ligne. Elles permettent aux sites web et applications de stocker, organiser et récupérer rapidement les informations que nous consultons chaque jour. Sans ces structures organisées, il serait impossible de naviguer sur des sites de commerce, d'utiliser les réseaux sociaux ou même de consulter ses emails.
Les différents types de bases de données utilisées sur Internet
Le paysage des bases de données s'est considérablement diversifié depuis les débuts d'Internet. Les bases de données relationnelles (SQL) restent les plus répandues. Elles organisent les informations en tables reliées entre elles par des relations logiques, à l'image d'Excel mais avec une puissance bien supérieure. MySQL, PostgreSQL et Microsoft SQL Server figurent parmi les plus utilisées. Ces systèmes sont adaptés pour les données structurées comme les catalogues de produits ou les informations clients.
Face à l'explosion du volume de données non structurées, les bases NoSQL ont gagné en popularité. Contrairement aux bases SQL, elles ne s'appuient pas sur un schéma rigide et se déclinent en plusieurs types : bases clé-valeur, orientées document, orientées colonne ou encore orientées graphe. MongoDB et Cassandra sont des exemples populaires. Ces systèmes répondent aux besoins du Big Data et des applications web en temps réel.
D'autres modèles ont également leur place dans l'écosystème : les bases de données orientées objet qui regroupent les données en objets, les bases distribuées stockées sur plusieurs serveurs, ou encore les bases de données cloud qui profitent de la flexibilité des infrastructures virtualisées. La tendance actuelle favorise les bases de données en mémoire qui résident dans la RAM pour maximiser la vitesse d'accès aux données.
Comment les données sont organisées et récupérées
L'organisation des données suit généralement un modèle défini lors de la conception de la base. Dans le modèle relationnel, l'information est structurée en lignes et colonnes formant des tables, similaires à des feuilles de calcul. Chaque table contient des informations sur une entité spécifique (clients, produits, commandes) et des clés permettent d'établir des relations entre ces tables.
Pour récupérer des informations, les développeurs et Data Analysts utilisent principalement le langage SQL (Structured Query Language), qui permet d'interroger la base avec précision. Par exemple, une requête SQL peut extraire tous les clients ayant effectué un achat durant le dernier mois. Pour les bases NoSQL, d'autres méthodes d'interrogation sont utilisées selon le type de base.
Les Systèmes de Gestion de Base de Données (SGBD) jouent un rôle central dans ce processus. Ils agissent comme des intermédiaires entre les utilisateurs et les données physiques, assurant plusieurs fonctions vitales : contrôle des accès, maintien de l'intégrité, optimisation des performances via des index et autres techniques. Ces systèmes respectent généralement les principes ACID (Atomicité, Cohérence, Isolation, Durabilité) pour garantir la fiabilité des transactions.
Les métiers de la data comme Data Analyst, Data Scientist ou Data Engineer s'appuient sur ces systèmes pour transformer les données brutes en informations exploitables. Ils utilisent des outils comme Python, Power BI ou des processus ETL (Extract, Transform, Load) pour analyser les données et générer des visualisations qui aident à la prise de décision.